SQL Server and the Adaptive Join feature: "Adaptive Join" Vs. "wrong cardinality estimate" and "Uneven data distribution"
Hi Guys,

Adaptive Join

However, when the same query is run again, the execution plan is retrieved from the cache but may not be optimal if the data is different.

- Cardinality estimate
- Uneven data distribution
Let's first talk about cardinality estimation.
We have talked several times about cardinality estimation and statistics, for example I highly recommend reading here for all the details:
- Inside the SQL Server Query Optimizer - part 3 Cardinality estimation
- SQL Server. Statistics, cardinality estimation and some thoughts about my previous post
To summarize quickly:
SQL Server uses statistics to estimate the cardinality. However the cardinality is not computable in exact way where the predicate of a Query containt more than one condition.
Suppose infact to have a Query with this predicate:
SELECT ID FROM PERSON WHERE GENDER = 'M' AND AGE < 30
I know from the statistics that exist on the GENDER field of the table PERSON that there are <N> rows with GENDER equal to 'M'
I always know from the statistics that there are 'N' rows in our table with the field AGE < 30
But the fact is that the number of rows returned from our query can range from 0 to the minimum between M and N.
Just for example think to the case where all the people with age < 30 have all the gender = 'F'
Yes SQL Server uses a formula to estimate the number of rows returned .... but in fact it is an estimate
And an inaccurate estimate can lead, for example, to the use of a non-optimal JOIN type.
Let's talk now about Uneven data distribution.
Data could have natuarally an uneved distribution. What do i mean?
Let's take an example thinking about the case of sales orders: we have sales orders with many rows and sales orders with just a few rows.
Let's assume that the first time the query is run we are in the case where we have a few rows. A nested loop operator will likely be chosen in the execution plan.
The exection plan is now cached in the plan cache.
The next time the query is run we are instead in the case where we have many rows. This time the nested loop join is not the optimal choice! In this case we have a performance problem!
The same happens in the opposite case.
Yes, there are solutions that allow you to limit the problem but do not solve it at the root.
The adaptive queries should solve these two problems!
Our first Adaptive Join
Let's see how a Query is performed with the Adaptive Join feature.
We have a master table with a clustered index on the ID field and a non clustered index con the PRICE field:
SELECT ID, PRICE FROM ADAPTIVEJOINSAMPLEMASTER
SELECT ID, IDADAPTIVEJOINSAMPLEMASTER FROM ADAPTIVEJOINSAMPLEDETAIL
Now let's execute the Query below:
SELECT
*
FROM ADAPTIVEJOINSAMPLEDETAIL D
JOIN ADAPTIVEJOINSAMPLEMASTER T ON D.IDADAPTIVEJOINSAMPLEMASTER = T.ID
WHERE
T.PRICE <= 5 AND T.ID > 1000000
Let's look at the execution plan.
Ok! we are using the new Adaptive Join operator!

Note that an adaptive Join has 3 inputs (and not only 2 like all the other operators).
If a statement is eligible to use the Adative Join the related property "is Adaptive" is set to True:


Examples
To disable the feature we are testing, instead of changing the compatibility level we will use the following option:
OPTION (USE HINT('DISABLE_BATCH_MODE_ADAPTIVE_JOINS'));
First (important) example
I call this example "Adaptive Join Vs. Wrong cardinality estimate"
Suppose we have the following query:
SELECT *
FROM ADAPTIVEJOINSAMPLEMASTER t
JOIN ADAPTIVEJOINSAMPLEDETAIL D ON D.IDADAPTIVEJOINSAMPLEMASTER = T.ID
WHERE
t.Id >= 1000102 AND -- 8.183
(t.Price > 5 or t.Price = 2) -- 18.141
OPTION (USE HINT('DISABLE_BATCH_MODE_ADAPTIVE_JOINS'));
In this simple master-detail Query, the master Query (AdativeJoinSampleMaster) have:
- a clustered index Index on the Id field
- a non clustered index on the Price Field.
The predicate contain more than one condition with both OR and AND operators.
There are 8.183 rows with T.Id greater or equal than 1000102 and 18.141 rows with t.price greater than 5 or price equal to 2.
Now, SQL Server does its best to calculate cardinality. It needs to know how many rows are extracted by this operation in order to choose which operatore use for the JOIN operations.
Basically if there are only a few rows to join, it is better to use a nested loop join. While if we have many rows the best type of join could be a Hash join or a Merge Join.
A nested loop will have poor performance with many rows to process. A hash join will be slower than a nested loop if the rows are few.
But let's get back to us.
We talked about how the optimizer calculate cardinality here
In our case, using its formulas, the optimizer estimates that 5687 rows will be extracted

Instead only one row is extracted!

If now we take a look to the execution plan we can see that a Hash Match operator is used

Let's now execute the same Query with the adaptive Join feature enabled:
SELECT *
FROM ADAPTIVEJOINSAMPLEMASTER t
JOIN ADAPTIVEJOINSAMPLEDETAIL D ON D.IDADAPTIVEJOINSAMPLEMASTER = T.ID
WHERE
t.Id >= 1000102 AND -- 8.183
(t.Price > 5 or t.Price = 2) --18.141
If we now execute this statement again we have that the adaptive join knows that the number of input rows is equal to 1!

Looking at the Adaptive Join property we can clearly see that a nested loop join has been chosen.
This is because we have only one row, while if we had more than 147 rows the hash match type of join would have been used.

Good very very good! Avoiding an incorrect cardinality estimate is one way to go fast!
Second (important) example
Which i call "Adaptive Join Vs. Uneven data distribution"A tipical example are sales order where There are orders with few rows and orders with many rows. In this case the data are unevenly distributed!
but ... let's see our example...
We have the following master-detail Query with a parameter
DECLARE@Price int = 3;
SELECT *
FROM AdaptiveJoinSampleMaster t
JOIN AdaptiveJoinSampleDetail d ON d.IdAdaptiveJoinSampleMaster = t.id
WHERE
(t.Price = @Price)
OPTION (USE HINT('DISABLE_BATCH_MODE_ADAPTIVE_JOINS'));
We can see that an hash join is used:

DECLARE@Price int = 169700452;
SELECT *
FROM AdaptiveJoinSampleMaster t
JOIN AdaptiveJoinSampleDetail d ON d.IdAdaptiveJoinSampleMaster = t.id
WHERE
(t.Price = @Price)
OPTION (USE HINT('DISABLE_BATCH_MODE_ADAPTIVE_JOINS'));
The join type remains a hash join even if only 2 rows are extracted

A Nested loop would have been more correct!
Without parameters the right join type would have been chosen, however, two different execution plans would have been generated.
Now let's try what happens by letting SQL Server use the Adaptive JOIN feature.
This time we will not use the parameters.
SELECT *
FROM AdaptiveJoinSampleMaster t
JOIN AdaptiveJoinSampleDetail d ON d.IdAdaptiveJoinSampleMaster = t.id
WHERE
(t.Price = 3)
If we execute the Query we will see that Adaptive Join in used.

A Hash match Join is choosen. (he have more than 20k rows in the master table)

If now i change the value of the price..
SELECT *
FROM AdaptiveJoinSampleMaster t
JOIN AdaptiveJoinSampleDetail d ON d.IdAdaptiveJoinSampleMaster = t.id
WHERE
(t.Price = 169700452)
The Query will return only 2 rows.
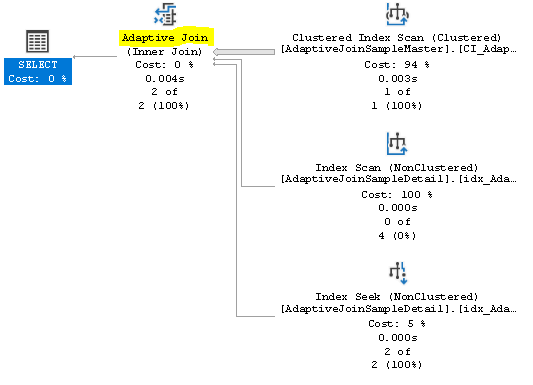
A nested loop is choosen.


Next post:
Previous post: SQL Server, Recover a corrupted database with Stellar Repair for MS SQL. The review!



Comments
Post a Comment