SQL Server, the Predicate and the Residual Predicate property of the Execution Plan
Hi Guys,

Are you sure you know everything? ...otherwise you should invest a few minutes to read this post!
We will use the Management Studio (SSMS) to take a look at the execution plan of which, as usual, we always try to learn something new.
So..
Enjoy the reading mate!
Predicate and the Residual Predicate
This time we start by in this way!
The same table has a datedoc field in datetime format and a field customer_name of type Varchar.
CREATE TABLE ORDTES ( ID INT identity(1,1) PRIMARY KEY CLUSTERED ,
DATEDOC datetime,
CUSTOMER_NAME varchar(80)
) We have used this structure many times in previous posts.
Now suppose we need to search for a row of this table by datedoc and then by customer_name.
If this search has to be repeated often it might be useful to dedicate an index to this query.
We have these possibility:
- Create a non clustered index on the DATEDOC field
- Create a non clustered index on the DATEDOC field with include on the CUSTOMER_NAME field
- Create a non clustered index on both the fields: DATEDOC and CUSTOMER_NAME.
Let's populate the table with some data and then try, one by one, the three indexes to see how the data is extracted.
WITH CTE AS (
SELECT 1 AS Numb
UNION ALL
SELECT a.Numb + 1
FROM CTE a
WHERE a.Numb < 100000
)
INSERT INTOORDTES(DATEDOC,CUSTOMER_NAME)
SELECT
CASE
WHEN ROW_NUMBER()OVER(ORDER BY Numb) < 10000THEN'2022-05-12'
ELSE '2022-05-11'
END,
CASE
WHEN ROW_NUMBER() OVER (ORDERBYNumb) % 5 = 0 THEN 'Luke'
WHEN ROW_NUMBER()OVER(ORDERBYNumb) % 5 = 1 THEN 'Paul'
WHEN ROW_NUMBER()OVER(ORDERBYNumb) % 5 = 2 THEN 'Itzik'
WHEN ROW_NUMBER()OVER(ORDERBYNumb) % 5 = 3 THEN 'Priyanka'
WHEN ROW_NUMBER()OVER(ORDERBYNumb) % 5 = 4 THEN 'Rey'
ELSE ''
END
FROM CTE
OPTION (MAXRECURSION 0)
In detail:
We have inserted 100.000 Rows.
The Query is this:
SELECT DATEDOC,CUSTOMER_NAMEFROM ORDTES
WHERE DATEDOC >= '2022-05-12 00:00:00.000' AND DATEDOC <= '2022-05-12 00:00:00.000'
AND CUSTOMER_NAME = 'Luke'
The first index
The first index is:
CREATE INDEX Ordtes_datedoc ONORDTES(DATEDOC)
Execute now the query and take a look to the execution plan:

The index in the DATEDOC field is not used. Instead, the clustered index is used because the clustered index is the table itself sorted by the ID field.
This also happens because we would still have to go to the table to read the CUSTOMER_NAME field. This is the most advantageous way the optimizer has found.
You should note that the clustered index scan read all the rows of our table. This time we have 100.000 Rows.
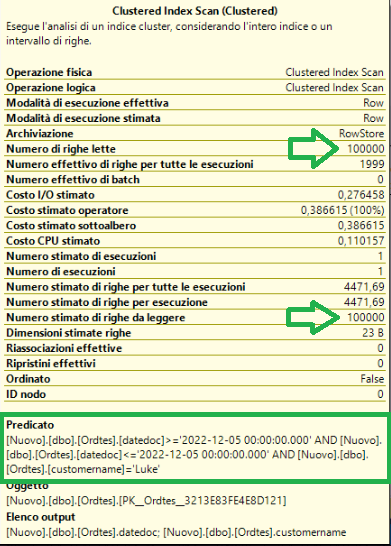
Looking at the property windows above you will note taht the Predicate property appears
It is now easy to understand what the predicate property means.
- DATEDOC >= '2022-05-12 00:00:00.000' AND DATEDOC <= '2022-05-12 00:00:00.000'
- CUSTOMERNAME = 'Luke'
If they are verified the record is returned otherwise it is discarded.
Simple isn't it?
The second index
The second index is:
CREATE INDEX ORDTES_DATEDOC_INCL_CUSTOMER_NAME ON ORDTES(DATEDOC) INCLUDE (CUSTOMER_NAME)
This time we added the CUSTORMER_NAME field in the INCLUDE clause.
The index cover every field of the query so it is a covering index: Most likely this index will be used.
Look at the exection plan:

Yes the index is used:

These 10.000 Rows will be returned directly from the index then ... whats happen?
We have a Predicate that this time is called Residual Predicate!
The residual predicate act as a filter.
For each of the 10.000 Rows, the condition on customer_name is checked to be true.
At the end of the process 1.999 Rows will be returned, other 8001 Rows will not be returned.
It is not easy again?
Third index.
CREATE INDEX ORDTES_DATEDOC_CUSTOMER_NAME ON ORDTES(DATEDOC,CUSTOMER_NAME)
Executing the Query the index is used:


Today we have seen what the predicate is and how it works
To sum up SQL Server is able to use an index to resolve a first predicate and iterate the same index to another field to resolve a second predicate.
That's all for today & Stay tuned for the next post!
If you are genuinely and truly interested in one of the products that appear in advertising ... click the adv from my blog to support my site!
Or click the ( ) ![]() button
button

Previous post: SQL Server, Is a Seek Always Only a Seek? Singleton Lookup and Range Scan. Part 2 ...some other infos.



Comments
Post a Comment