SQL Server 2019 and the Batch Mode on Rowstore
Hello everyone!

Welcome back guys,
Are you ready to continue the roundup of the new features introduced by SQL Server 2019?
Let's talk about Batch Mode on RowStore.
But first we need to take a step back to see what a Batch is!
What is a batch?
Simply stated, a batch is an internal 64 KB wide storage structure that contains a group of rows ranging from 64 to 900 depending on the number of columns of which they are composed.
Each column used by the query is stored in a continuous column vector of fixed-size elements, where the qualifying row vector indicates which rows are still logically part of the batch:
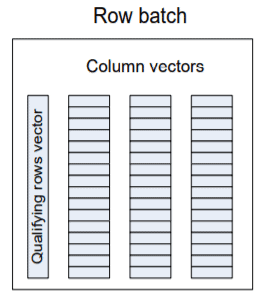
For instance, when a batch mode filter operation needs to qualify rows that meet a given column filter criteria, all that is needed is to scan the vector that contains the filtered column and mark the row appropriately in the qualifying rows vector, based on whether or not the column value meets the filter criteria.
What are the benefits of using batches?
SQL Server in fact evaluates the metadata only once for the whole batch instead of doing it for each row.
In this way the CPU usage is reduced and the processor cache is exploited in a better way.
However, they were added only to support tables and queries where columnstore indexes were present and for this reason the feature was called Batch Mode on ColumnStore.
Today with SQL Server 2019 the same feature is also made available for tables in which the processing takes place by row and is therefore called Batch Mode on RowStore.
Are you ready?
Batch Mode on Rowstore
Create Table moviments
(id int identity (1,1),
year int, Qty float,
Price float,
Classificators VarChar(10)
)
Then we set the compatibility level to 140 (SQL Server 2017) and execute the following Query:Insert into movimenti (year,Qty,Price,Classificators) values (1980, 1,1.5, 'A')
Now let's analyze the results:SELECTClassificators, SUM(Qty), SUM(Price) FROMmovimentsGROUP BYORDER BYClassificatorsClassificators
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 6 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
(1 row affected)
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Table 'moviments'. Scan count 1, logical reads 690, physical reads 0, page server reads 0, read-ahead reads 690, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
SQL Server Execution Times:
CPU time = 125 ms, elapsed time = 145 ms.
Completion time: 2021-10-08T14:52:58.7186017+02:00
With a table filled with 140.000 of rows we have a CPU time of 125 ms and an elapsed time of 145 ms.

SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
(1 row affected)
Table 'moviments'. Scan count 1, logical reads 690, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
(1 row affected)
SQL Server Execution Times:
CPU time = 31 ms, elapsed time = 71 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
Completion time: 2021-10-08T14:54:38.9217244+02:00
And this is the execution plan with the Execution Mode Batch.

- Execution time reduces from 145 to 71 ms.
- CPU Time reduces from 125 to 31 ms

Indeed, its use is always a cost-based decision.
For example, if the table has fewer than 131071 rows (a magic number) the batch mode on the Rowstore is not used.
Simply the Optimizer has its own (complicated) heuristics.
- In the Query at least one table must have not less than 131072 rows
- Should be present at least an efficient batch operator (join, aggregate or window aggregate)
- At least one of the batch operators should have in input no fewer than 131072 rows.
Luca Biondi @ SQLServerPerformance blog!



Comments
Post a Comment