SQL Server: Transactions, Lock e Deadlock. A little bit of theory explained in a simple way!
Hi guys,

Today
I wanted to talk to you about some basic concepts related to relational
databases that are absolutely worth knowing!.
We will talk about Transactions, lock and
also about a particular type of lock called deadlock.
I'll tell you some theory but don't worry: as
usual I will try to be as clear as possible!
You are ready? So happy reading!!!
What is a transaction?
A transaction is a sequence of operations which, if completed without errors, produces a change of state in our database.
For example:
BEGIN TRAN INSERT INTO TABLE_A (CAMPO1, CAMPO2) VALUES ('VAL1','VAL2') INSERT INTO TABLE_B(CAMPO1,CAMPO2,CAMPO3) VAULES ('VAL1','VAL2','VAL3') COMMIT
orINSERT INTO TABLE _A (CAMPO1, CAMPO2) VALUES ('VAL1','VAL2')
In the first case we are talking about explicit transaction, in the second of implicit transaction.
…and therefore what we need to understand?
We understand that we are always dealing with a transaction.
If we are the ones to explicitly open a transaction through the BEGIN TRAN command, SQL Server will, behind the scenes, open an implicit one before the T-SQL command is executed.
It is not easy?
Now let's go a step further and say which are the logical properties that the transactions must respect.
To
remember them by heart just remember the initials: ACID!
The first letter "A" stands for Atomicity.
Atomicity means that the transaction is
indivisible and that its execution must be either total or null.
In practice, when our operation comes to an end
we have two possibilities:
COMMIT the transaction thus making the changes
persistent, or
ROLLBACK
the transaction canceling any changes.
The second letter "C" stands for Consistency.
This property says that when a transaction
begins, a database must be in a consistent state. When the transaction ends,
the database must be in another consistent state.
To
achieve this consistency, integrity constraints or domain constraints must not
be violated.
The Third property called Isolation
instead requires that each transaction must be performed in an isolated and
independent way from the other transactions.
Failure
of one transaction must not interfere with other running transactions
Finally we have the fourth and last property
represented by the letter "D" which stands for Durability.
What does durability mean?
Durability
means that once the transaction has been committed, the changes made must no
longer be lost.
Transaction Log
Speaking of durability we have to open a small parenthesis to introduce the concept of transaction log.
It is often thought that SQL Server satisfies
the durability property by immediately writing data to disk but this is
actually not true
The
mechanism is in fact based on another one and is called WRITE AHEAD LOGGING
or WAL.
This
mechanism is adopted to avoid that, between the moment in which SQL Server
"commits" to write the data and the moment in which this data is
actually written, problems due to a malfunction may occur.
A log is kept in which all the operations
that are performed on the database are noted. This vital log is called the Transaction Log
Let's say that this log is essential because in
case of malfunction it will always be possible to recover the data by
re-reading the transaction log.
If,
on the other hand, it is the transaction log that is damaged, the recovery of
non-committing information will not be possible.
The Locks
Now
let's take it a step further by asking ourselves this question:
How does SQL Server handle transactions?
Or
how does it make sure that the four ACID properties just explained are
respected?
Simple, it does this by imposing and
releasing locks.
The following basic rules apply:
- If a transaction imposes a lock on an object, all other transactions that require access to the same object must wait until that lock is released.
- While an object is locked, other transactions will not be able to make any changes to the data stored in that object. Only after the lock is released by commit or rollback will other transactions be able to modify the data.
The matter is vast so let's see more
information on locks.
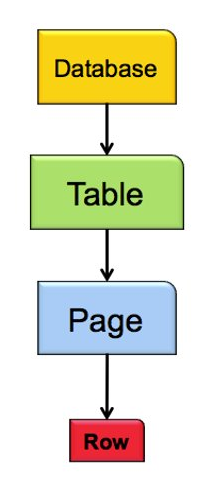
Locks can be placed on different objects such as
the database, tables, pages or rows of tables.
Locks also have a hierarchy which you can see
below:

Let's now see the four types of locks:
A) The Exclusive lock (X) is a type of
lock that is used to prevent other transactions from modifying or reading
the locked object..
NB: This type of lock can be imposed on a page
or on a row only if there is no other lock of type Shared (S) or Exclusive (X).
B) The Shared (S) lock is instead a type
of lock that is placed on a page or row type object to declare that it is only
available for reading. It therefore prevents other transactions from modifying
the object that holds the lock.
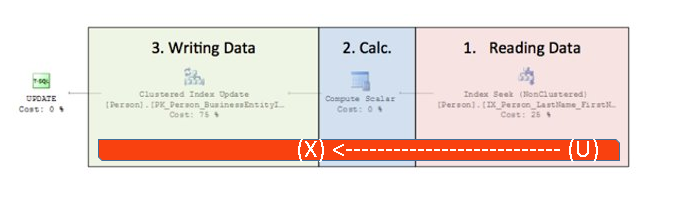
C) The third lock called Update (U) is a
type of lock used precisely in Updates.
Unlike an Exclusive lock, it can be imposed on
an object that already has a Shared lock. During an update, before the Write
phase, the Update (U) lock becomes Exclusive (X)

D) Finally, the last lock is called Intent
(I).
It is set when SQL Server wants to acquire a
Shared or Exclusive (X) type lock on a resource placed at a lower level as a
hierarchy.
When a page or row is locked, an intent (I) lock
is placed on the table.
It is a type of lock not strictly necessary for
SQL server but is used to improve performance.
For example, an Intent Shared Lock tells SQL
Server that there will be a Shared lock at a Lower hierarchy level.
But why does it serve to improve performance?
The reasoning is simple:
To acquire an Exclusive type lock at the table
level, SQL Server needs to know whether or not there is an incompatible lock
type (such as S or U) somewhere in the record.
Here,
without the Intent locks SQL Server should check each record for an
incompatible lock.
Deadlocks
We now come to a particular type of lock called deadlock.
When does a deadlock happen?
A deadlock occurs when two or more processes acquire a
lock on different objects and
which subsequently
attempt to acquire another lock on an object previously locked by another
process.

Let's take an example:
We
have two tables that we will call table A and table B.
Let's imagine that a user we call A opens a
transaction and updates table A.
Then
comes another user we call B who in turn opens a transaction and updates table
B.
At this point the first user A makes a select on
table B.
The
select will be waiting because table B is locked.
At this point, if the second user B makes a
select on table A, a deadlock is generated.
If you notice, in fact, the select on table B made by
user A waits for table B to be unlocked.
Likewise,
the select made by user B on table A waits for table A to be unlocked.
So what? How do you get out of this situation?
Fortunately, SQL Server detects this type of
problem and acts by killing one of the two processes.
• The process that is terminated is called victim.
• The process that will come to an end at this point is called winner.
But how does SQL Server choose the victim and
the winner?
SQL Server chooses the process that requires
the least resources to be canceled as the victim.
A tip to avoid deadlocks? try to have
transactions as short as possible by trying for example to optimize the Queries
within the transactions.
That's all for today!
I hope you enjoyed the article!
Have a great week and share knowledge!!!
Luca Biondi @ SQLServerPerformance blog 2021!
notes:
The intention was to tell you about the concepts of transaction, lock and deadlock.
In order not to put too much meat on the fire, I have deliberately omitted topics such as optimistic and pessimistic competition, I have told you about the levels of isolation and lock escalation. We haven't even given examples to see locks in action.



{kind=link}
{kind=link}
{kind=link}
Comments
Post a Comment